Abstract
We propose a differentiable nonlinear least squares framework to account for uncertainty in relative pose estimation from feature correspondences. Specifically, we introduce a symmetric version of the probabilistic normal epipolar constraint, and an approach to estimate the covariance of feature positions by differentiating through the camera pose estimation procedure. We evaluate our approach on synthetic, as well as the KITTI and EuRoC real-world datasets. On the synthetic dataset, we confirm that our learned covariances accurately approximate the true noise distribution. In real world experiments, we find that our approach consistently outperforms state-of-the-art non-probabilistic and probabilistic approaches, regardless of the feature extraction algorithm of choice.
Overview
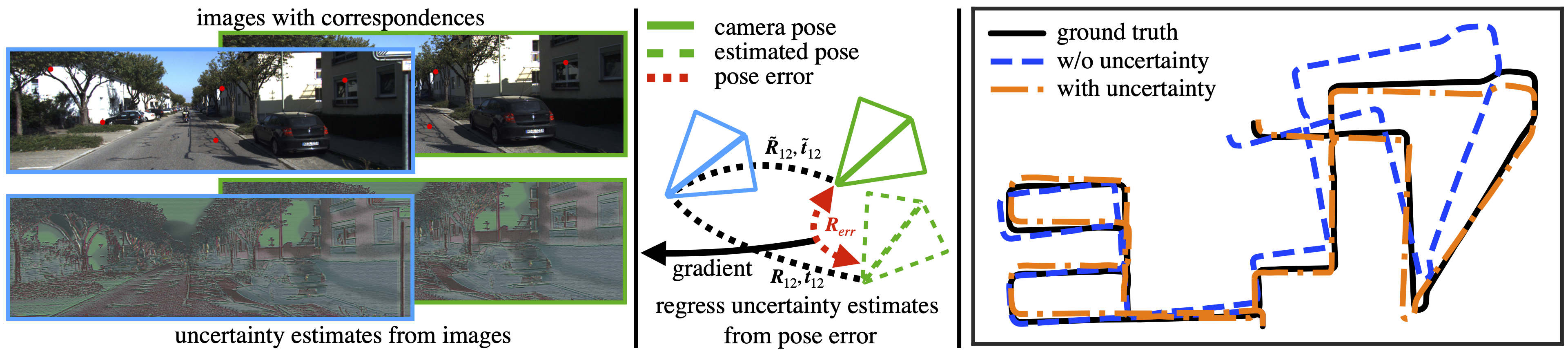 a) We propose a symetric extension of the Probabiltistic Normal Epipolar Constraint (PNEC) to more accurately model the geometry of relative pose estimation with uncertain feature positions.
a) We propose a symetric extension of the Probabiltistic Normal Epipolar Constraint (PNEC) to more accurately model the geometry of relative pose estimation with uncertain feature positions.
b) We propose a learning strategy to minimize the relative pose error by learning feature position uncertainty through differentiable nonlinear least squares (DNLS). This learning strategy can be combined with any feature extraction algorithm. We evaluate our learning framework with synthetic experiments and on real-world data in a visual odometry setting. We show that our framework is able to generalize to different feature extraction algorithms such as SuperPoint and feature tracking approaches.
Method
 Dense Uncertainty Prediction Color-coded for visualization.
Dense Uncertainty Prediction Color-coded for visualization.
We want to estimate keypoint positional uncertainties $\boldsymbol{\Sigma}_{2\text{D}}, \boldsymbol{\Sigma}^\prime_{2\text{D}}$ in the images such that minimizing the PNEC energy function
$$
\boldsymbol{R} = \text{arg min}_{\boldsymbol{R}} E(\boldsymbol{R}, \boldsymbol{t})
$$
$$
E(\boldsymbol{R}, \boldsymbol{t}) = \sum_i \frac{e_i^2}{\sigma_i^2} = \sum_i \frac{| \boldsymbol{t}^\top (\boldsymbol{f}_i \times \boldsymbol{R} \boldsymbol{f}^\prime_i) |^2}{\boldsymbol{t}^\top (\hat{(\boldsymbol{R} \boldsymbol{f}^\prime_i)} \boldsymbol{\Sigma}_i \hat{(\boldsymbol{R} \boldsymbol{f}^\prime_i)}{}^\top + \hat{\boldsymbol{f}_i} \boldsymbol{R} \boldsymbol{\Sigma}^\prime_i \boldsymbol{R}^\top \hat{\boldsymbol{f}_i}{}^\top) \boldsymbol{t}}
$$
leads to a minimal positional error (see paper for more details). Using implicit differentiation we can get the gradient of the pose error $e_{\text{rot}}$ with regard to the image uncertainties as
$$
\frac{d \mathcal{L}}{d \boldsymbol{\Sigma}_{2\text{D}}} = - \frac{\partial^2 E_s}{\partial \boldsymbol{\Sigma}_{2\text{D}} \partial \boldsymbol{R}{}^\top} \left(\frac{\partial^2 E_s}{\partial \boldsymbol{R} \partial \boldsymbol{R}{}^\top} \right)^{-1} \frac{e_{\text{rot}}}{\partial \boldsymbol{R}}
$$
allowing us to differentiate through to optimization and training an encoder-decoder network to predict dense uncertainty estimates for the whole image.
Architecture
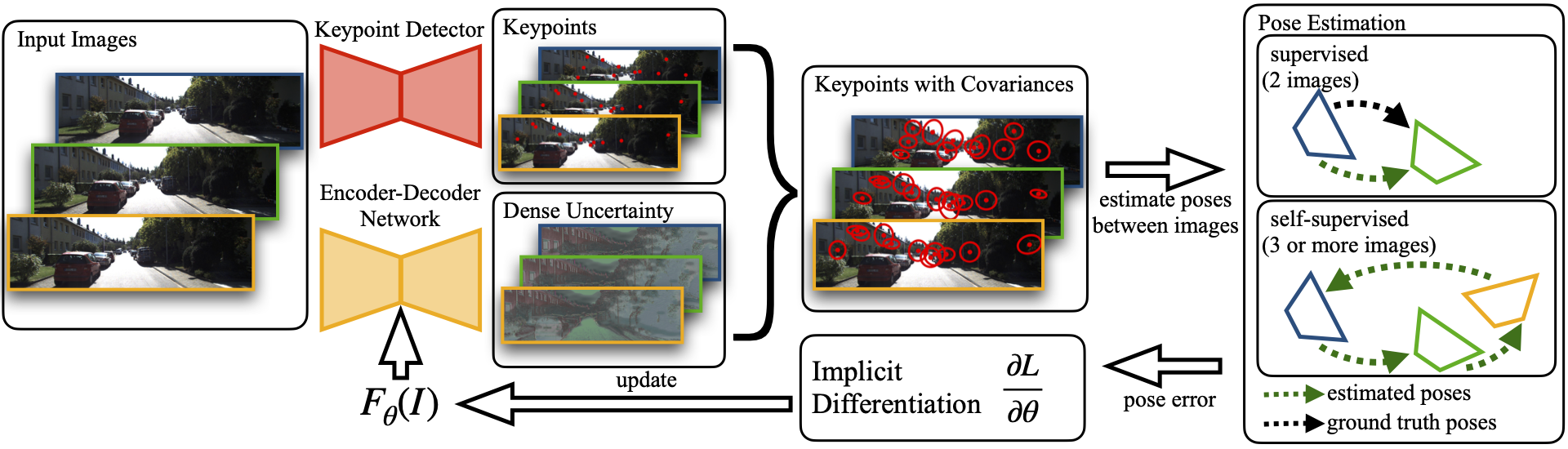 Training Scheme Overview.
Training Scheme Overview.
Supervised Learning
Given a dataset with accurate pose information we can train the encoder-decoder by comparing the estimated pose to the ground truth pose giving us following loss function: $$e_{\text{rot}} = \angle \tilde{\boldsymbol{R}}{}^\top \boldsymbol{R}$$
Self-Supervised Learning
For datasets without accurate ground truth pose information our framework allows to train the encoder-decoder in a self-supervised manner by exploiting the cycle consistency between a tuple of images such that the pose error is given by: $$e_{\text{rot}}=\angle \prod_{(i,j) \in \mathcal{P}} \boldsymbol{R}_{ij}$$
Results
We evaluate our framework using a combination of synthetic and real-world experiments. For the synthetic data, we investigate the ability of the gradient to learn the underlying noise distribution correctly by overfitting covariance estimates directly. We also investigate if better noise estimation leads to a reduces rotational error.
On real-world data, we use the gradient to train a network to predicts the noise distributions from images for different keypoint detectors. We train a network, both in a supervised and self-supervised manner, for SuperPoint and Basalt KLT-Tracks, since they follow different paradigms. We evaluate the performance of the learned covariances in a visual odometry setting on the popular KITTI odometry dataset. Results for the EuRoC dataset can be found in the paper.
Synthetic Experiments
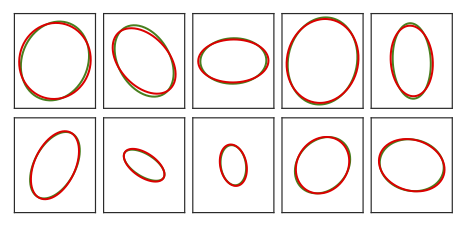
Synthetic Experiment. Estimated covariances (red) compared to ground truth covariances (green).
In the simulated experiments we overfit covariance estimates for a single relative pose estimation problem. For this, we create random relative pose estimation problem consisting of two camera-frames observing points in 3D space. The points are projected into camera frames using a pinhole camera model. We fix the noise in the first frame to be small, isotropic, and homogeneous in nature. Each projected point in the second frame is assigned a random gaussian noise distribution. From this $128\,000$ random problems are sampled with random relative poses. We learn the noise distributions by initializing all covariance estimates as scaled identity matrices, solving the relative pose estimation problem using the PNEC and updating the parameters of the distribution using the gradient directly. The figure shows, that with implicit differentiation, our framework can learn the correct distributions from noisy data by following the gradient that minimizes the rotational error.
Real World
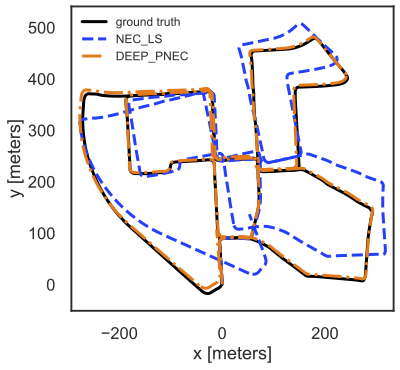
Trajectory. KITTI seq. 00. Visualization uses the ground truth translation scale as we do 2-view pose estimation.
We evaluate our method on the KITTI and EuRoC (see paper). For the supervised training of KITTI we choose sequences 00-07 as the training set and 08-10 as the test set. For the self-supervised training we also only train on sequences 00-07. We use a smaller UNet architecture as our network to predict the covariances for the whole image.

Visual Odometry Results. Rotation and translation error using SuperPoint keypoints.

Visual Odometry Results. Rotation and translation error using KLT keypoints.
The tables show the average results on the test set over 5 runs for SuperPoint and KLT tracks on KITTI, respectively. We show additional results in the supplementary material. Our methods consistently perform the best over all sequences, with the self-supervised being on par with our supervised training. Compared to its non-probabilistic counterpart NEC-LS, our method improves $\text{RPE}_1$ by 7% and 13% and the $\text{RPE}_n$ by 37% and 23% for different keypoint detectors on unseen data. Furthermore, it also improves upon methods that use weighting, like weighted NEC-LS and the non-learned covariances for the PNEC, significantly.